Publications
Here are my publications.
2024
-
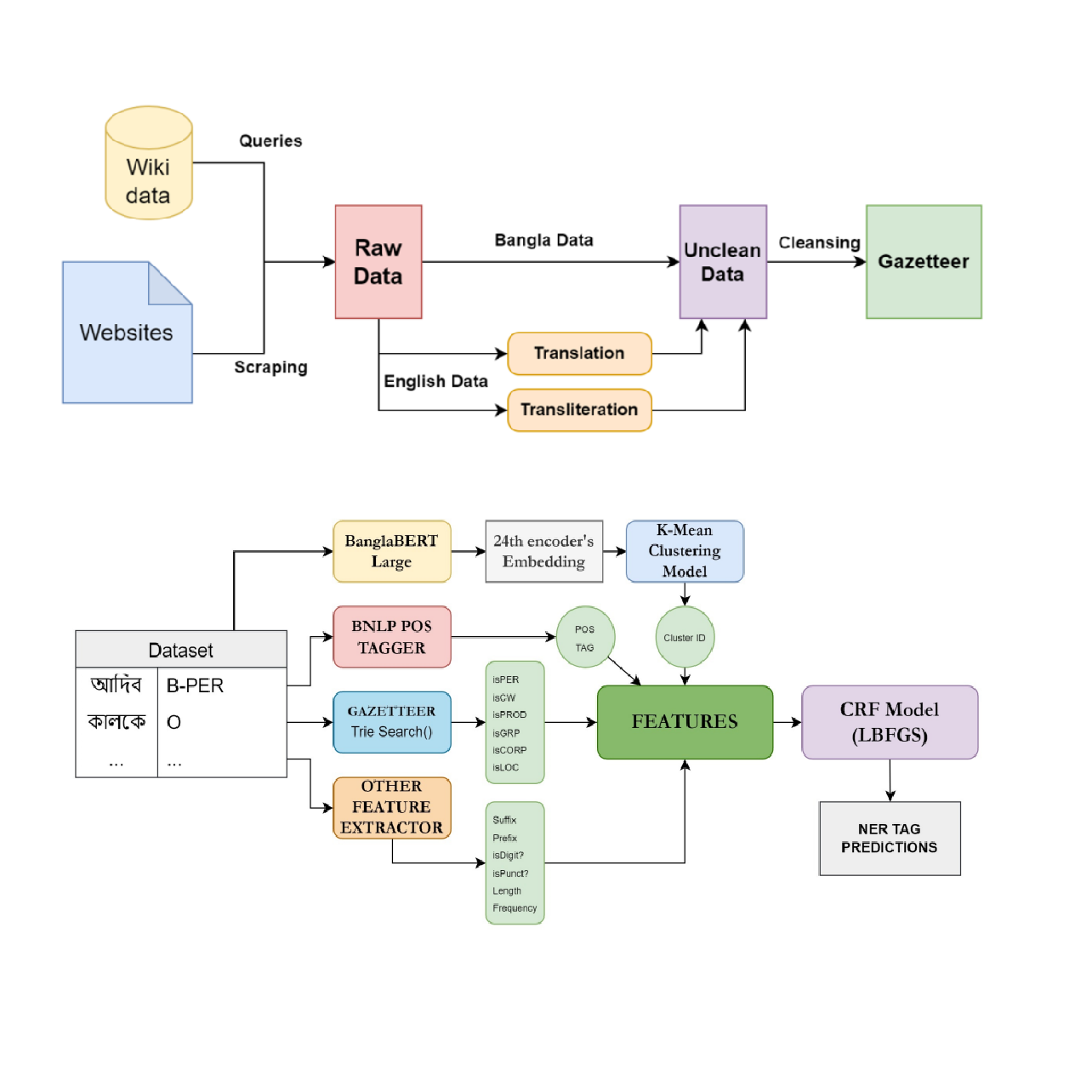 Gazetteer-Enhanced Bangla Named Entity Recognition with BanglaBERT Semantic Embeddings K-Means-Infused CRF ModelNiloy Farhan, Saman Sarker Joy, Tafseer Binte Mannan, and Farig Sadeque2024
Gazetteer-Enhanced Bangla Named Entity Recognition with BanglaBERT Semantic Embeddings K-Means-Infused CRF ModelNiloy Farhan, Saman Sarker Joy, Tafseer Binte Mannan, and Farig Sadeque2024Named Entity Recognition (NER) is a sub-task of Natural Language Processing (NLP) that distinguishes entities from unorganized text into predefined categorization. In recent years, Bangla NLP has seen advancements in various subtasks, but Named Entity Recognition in this language continues to face challenges, requiring dedicated efforts for improvement. In this research, we explored the existing state of research in Bangla Named Entity Recognition. We tried to figure out the limitations that current techniques and datasets have and we addressed these limitations. Additionally, we developed a Gazetteer that has the ability to significantly boost the performance of NER. We also proposed a new NER solution by taking advantage of our created Gazetteer and state-of-the-art NLP tools that outperform conventional techniques, especially for low-resource-languages like Bangla.
@misc{farhan2024gazetteerenhanced, title = {Gazetteer-Enhanced Bangla Named Entity Recognition with BanglaBERT Semantic Embeddings K-Means-Infused CRF Model}, author = {Farhan, Niloy and Joy, Saman Sarker and Mannan, Tafseer Binte and Sadeque, Farig}, year = {2024}, eprint = {2401.17206}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, }

2023
-
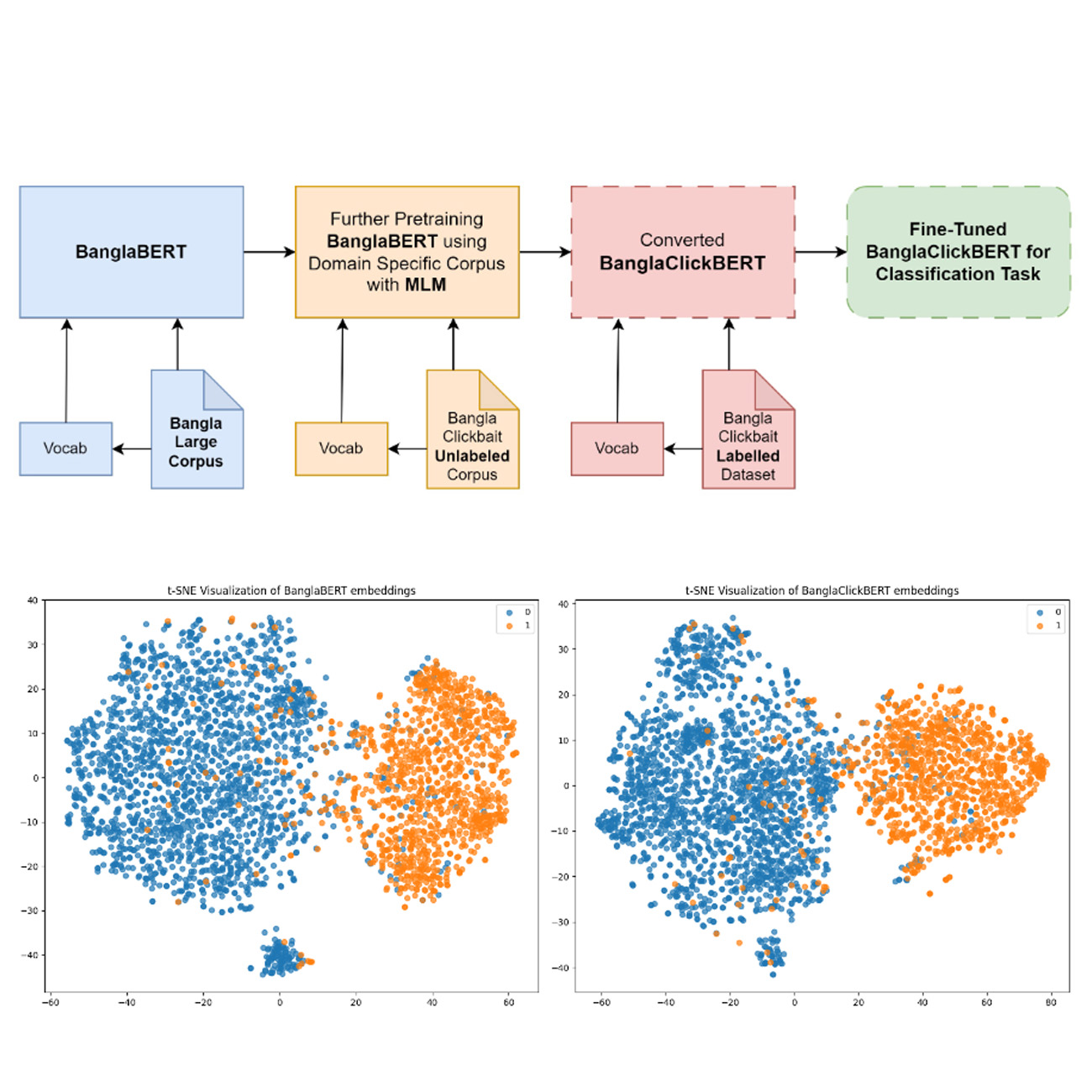 BanglaClickBERT: Bangla Clickbait Detection from News Headlines using Domain Adaptive BanglaBERT and MLP TechniquesSaman Sarker Joy, Tanusree Das Aishi, Naima Tahsin Nodi, and Annajiat Alim RaselIn Proceedings of The 21th Annual Workshop of the Australasian Language Technology Association, 2023
BanglaClickBERT: Bangla Clickbait Detection from News Headlines using Domain Adaptive BanglaBERT and MLP TechniquesSaman Sarker Joy, Tanusree Das Aishi, Naima Tahsin Nodi, and Annajiat Alim RaselIn Proceedings of The 21th Annual Workshop of the Australasian Language Technology Association, 2023News headlines or titles that deliberately persuade readers to view a particular online content are referred to as clickbait. There have been numerous studies focused on clickbait detection in English language, compared to that, there have been very few researches carried out that address clickbait detection in Bangla news headlines. In this study, we have experimented with several distinctive transformers models, namely BanglaBERT and XLM-RoBERTa. Additionally, we introduced a domain-adaptive pretrained model, BanglaClickBERT. We conducted a series of experiments to identify the most effective model. The dataset we used for this study contained 15,056 labeled and 65,406 unlabeled news headlines; in addition to that, we have collected more unlabeled Bangla news headlines by scraping clickbait-dense websites making a total of 1 million unlabeled news headlines in order to make our BanglaClickBERT. Our approach has successfully surpassed the performance of existing state-of-the-art technologies providing a more accurate and efficient solution for detecting clickbait in Bangla news headlines, with potential implications for improving online content quality and user experience.
@inproceedings{saman2023banglaclickbert, author = {Joy, Saman Sarker and Aishi, Tanusree Das and Nodi, Naima Tahsin and Rasel, Annajiat Alim}, booktitle = {Proceedings of The 21th Annual Workshop of the Australasian Language Technology Association}, title = {BanglaClickBERT: Bangla Clickbait Detection from News Headlines using Domain Adaptive BanglaBERT and MLP Techniques}, year = {2023}, archiveprefix = {ALTA 2023}, primaryclass = {cs.LG}, } -
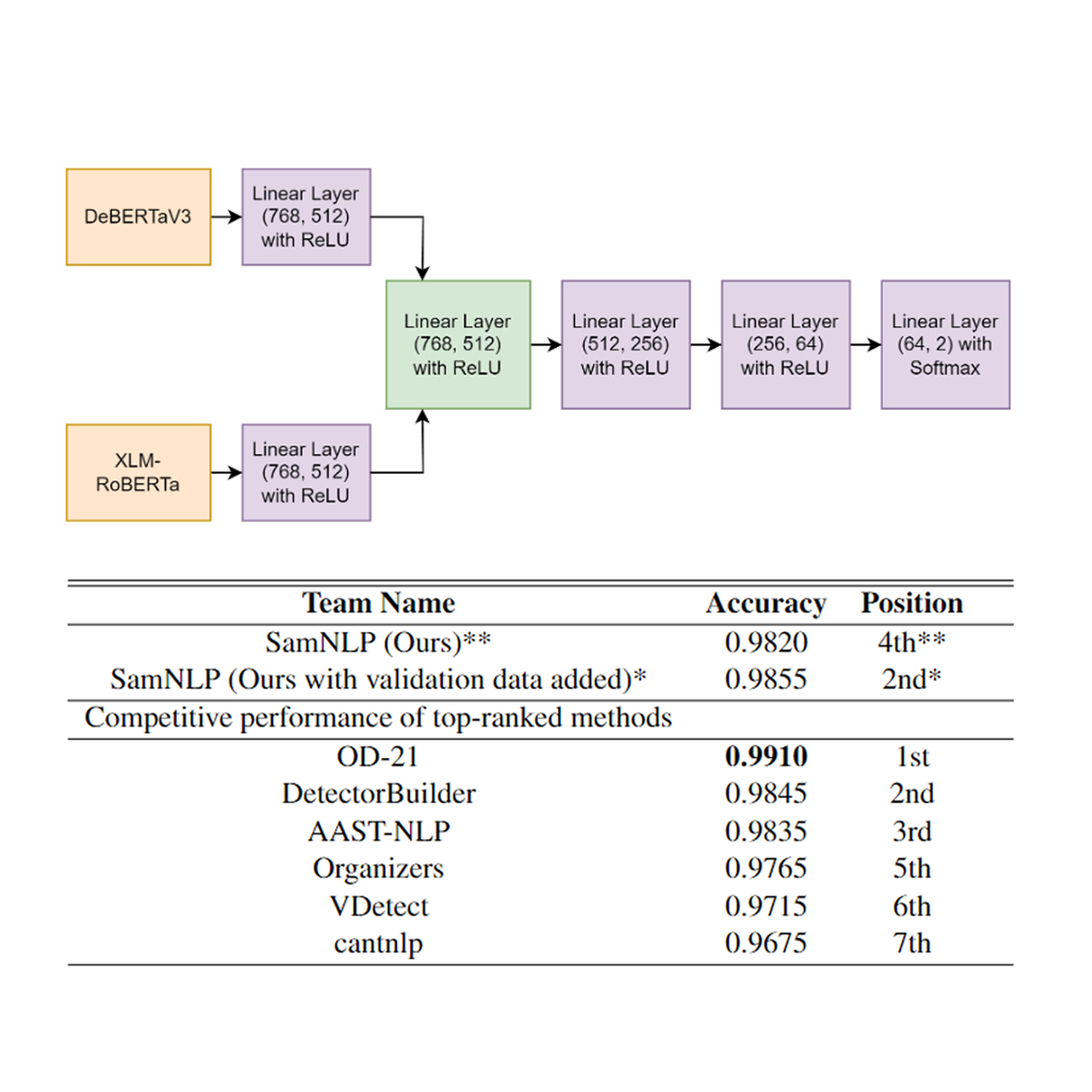 Feature-Level Ensemble Learning for Robust Synthetic Text Detection with DeBERTaV3 and XLM-RoBERTaSaman Sarker Joy, and Tanusree Das AishiIn Proceedings of The 21th Annual Workshop of the Australasian Language Technology Association, 2023
Feature-Level Ensemble Learning for Robust Synthetic Text Detection with DeBERTaV3 and XLM-RoBERTaSaman Sarker Joy, and Tanusree Das AishiIn Proceedings of The 21th Annual Workshop of the Australasian Language Technology Association, 2023As large language models, or LLMs, continue to advance in recent years, they require the development of a potent system to detect whether a text was created by a human or an LLM in order to prevent the unethical use of LLMs. To address this challenge, ALTA Shared Task 2023 introduced a task to build an automatic detection system that can discriminate between human-authored and synthetic text generated by LLMs. In this paper, we present our participation in this task where we proposed a feature-level ensemble of two transformer models namely DeBERTaV3 and XLM-RoBERTa to come up with a robust system. The given dataset consisted of textual data with two labels where the task was binary classification. Experimental results show that our proposed method achieved competitive performance among the participants. We believe this solution would make an impact and provide a feasible solution for detection of synthetic text detection.
@inproceedings{saman2023featurelevel, author = {Joy, Saman Sarker and Aishi, Tanusree Das}, booktitle = {Proceedings of The 21th Annual Workshop of the Australasian Language Technology Association}, title = {Feature-Level Ensemble Learning for Robust Synthetic Text Detection with DeBERTaV3 and XLM-RoBERTa}, year = {2023}, archiveprefix = {ALTA 2023}, primaryclass = {cs.LG}, }

